What is caches?
Caches are storage systems that save and reuse exact LLM requests. You can enable caches to reduce LLM costs and improve response times.Why Caches?
You may find caches useful when you want to:- Reduce latency: Serve stored responses instantly, eliminating the need for repeated API calls.
- Save costs: Minimize expenses by reusing cached responses instead of making redundant requests.
How to use Caches?
Turn on caches by settingcache_enabled to true. We currently will cache the whole conversation, including the system message, user message and the response.
See the example below, we will cache the user message “Hi, how are you?” and its response.
- OpenAI Python SDK
- OpenAI TypeScript SDK
- Standard API
- Other SDKs
Caches parameters
Enable or disable caches.
This parameter specifies the time-to-live (TTL) for the cache in seconds.
It’s optional and the default value is 30 days now.
This parameter specifies the cache options. Currently we support
cache_by_customer option, you can set it to true or false. If cache_by_customer is set to true, the cache will be stored by the customer identifier.It’s an optional parameter
How to view caches
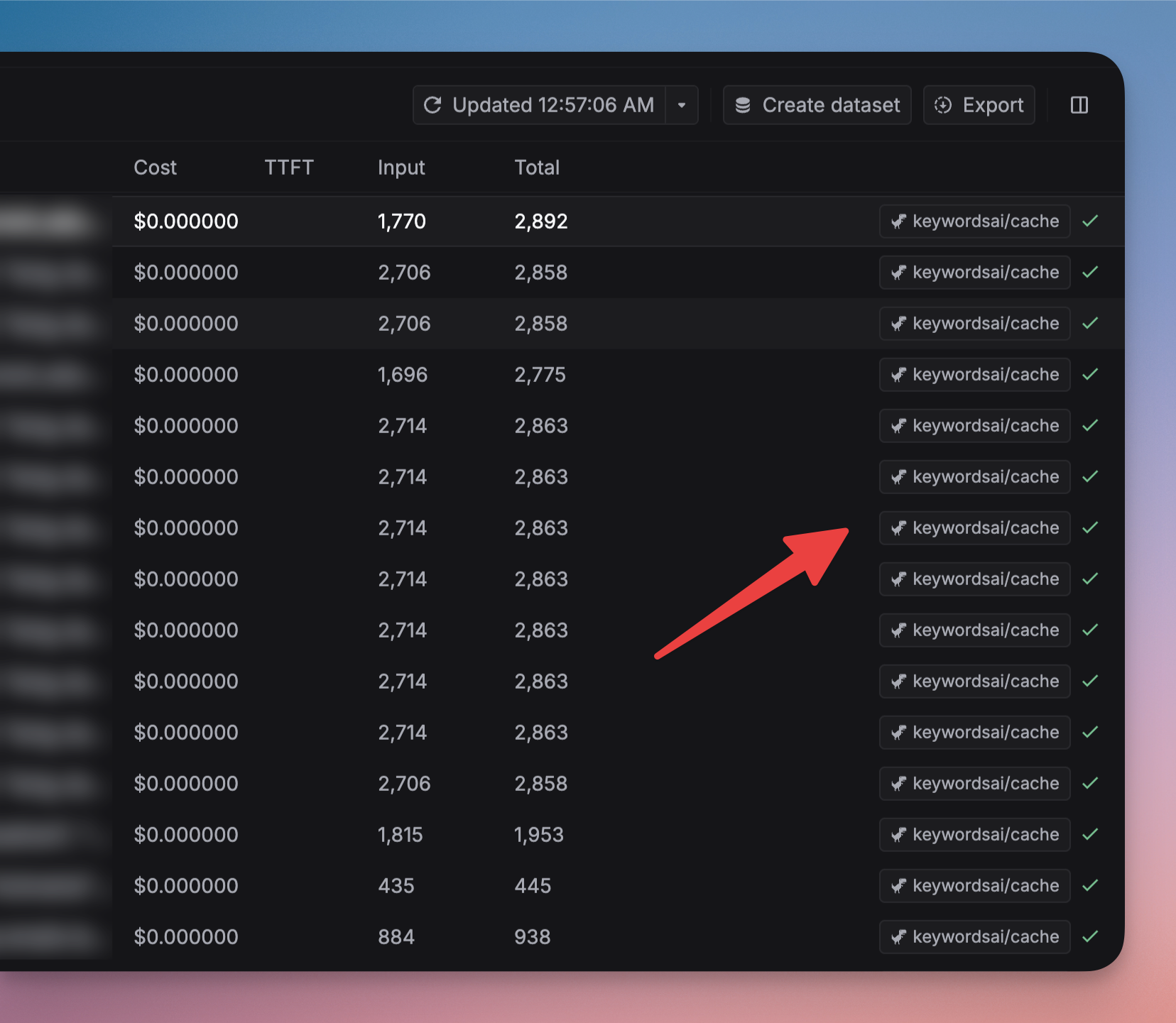
You can view the caches on the Logs page. The model tag will bekeywordsai/cache. You can also filter the logs by the Cache hit field.
Omit logs when cache hit
You can omit the logs when cache hit by setting theomit_logs parameter to true or go to Caches in Settings.
So this won’t generate a new LLM log when the cache is hit.