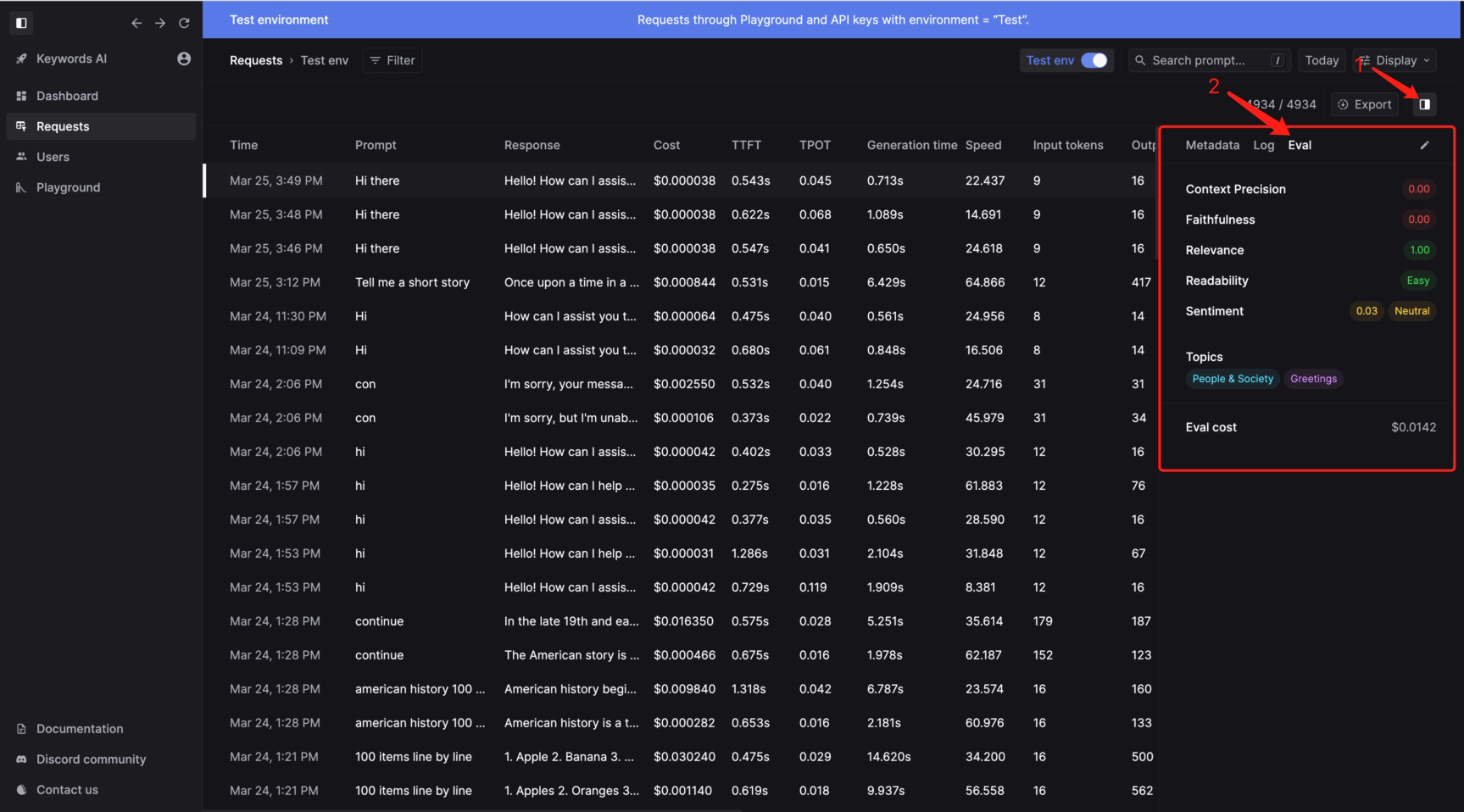
Deterministic metrics (read more)
Below is the list of deterministic metrics that measure the relationship between the generated answer and the retrieved contexts.- ROUGE-L precision measures the longest common subsequence between the generated answer and the retrieved contexts.
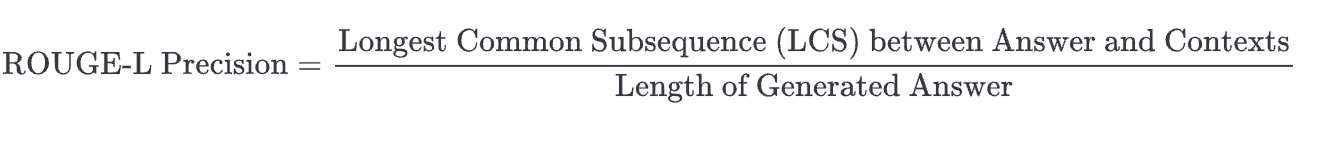
- Token overlap precision calculates the precision of token overlap between the generated answer and the retrieved contexts.
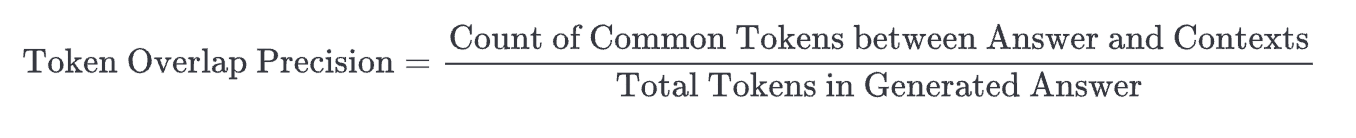
- BLEU (Bilingual Evaluation Understudy) calculates the n-gram precision. (Below:
p_nis the n-gram precision,w_nis the weight for each n-gram, and BP is the brevity penalty to penalize short answers)
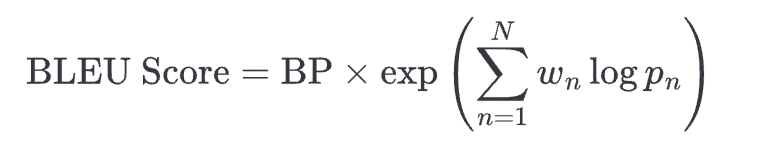
- Rouge|Token Overlap|Bleu Faithfulness is defined as the proportion of the sentences in the generated answer that can matched to the retrieved context above a
threshold.
threshold as 0.5.

LLM-Based metrics (read more)
Keywords AI prompts the LLM to calculate faithfulness based on classifying faithfulness by statement:classify_by_statement = TRUE where LLM is prompted to evaluate the faithfulness of each statement in the Generated Answer and outputs a float score:

Settings and parameters
- Go to Keywords AI (on top of the left nav bar) > Evaluation > Text generation > Faithfulness
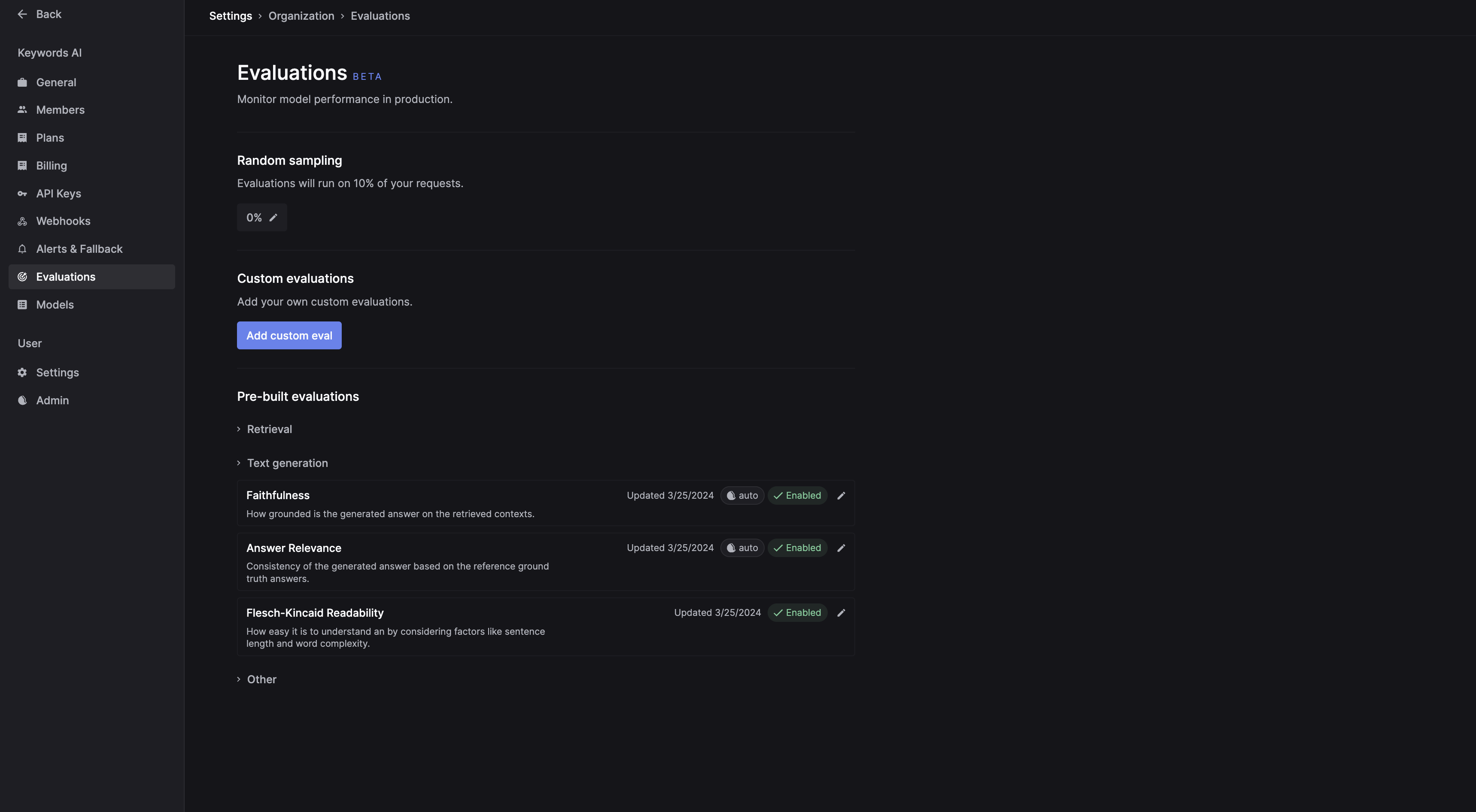
- Click on the
Faithfulnesscard to create the setting:
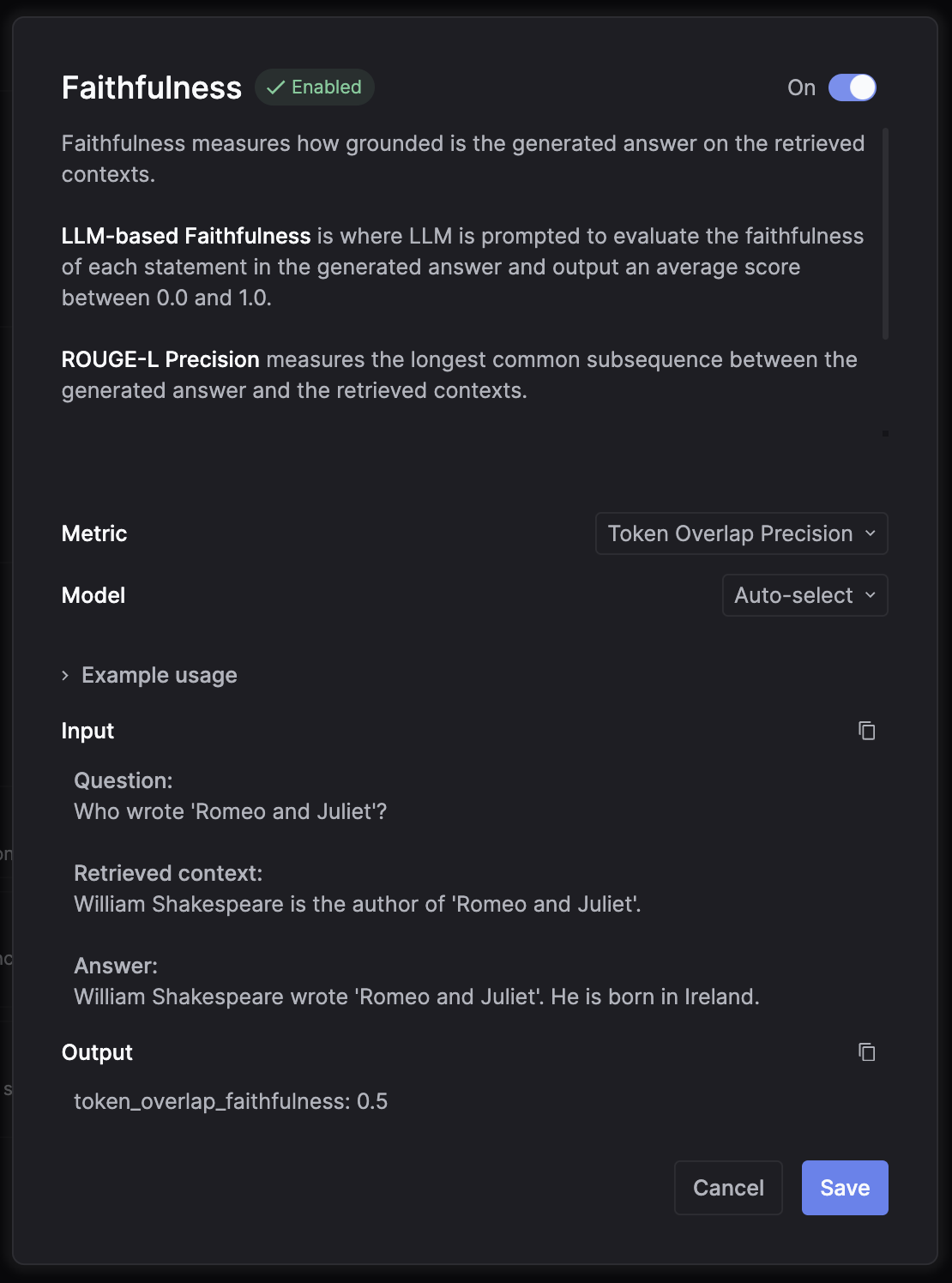
- Click the enable switch to turn on the evaluation
- Pick which method you want to use:
- LLM-based
- ROUGE-L Precision
- Token Overlap Precision
- BLEU
- Pick a LLM model you want to run the evaluation with (if you choose LLM-based method)
- Hit the “Save” button.
-
Make an API call, and the evaluation will be run based on the
Ramdom samplingsetting. - Check results in the requests log