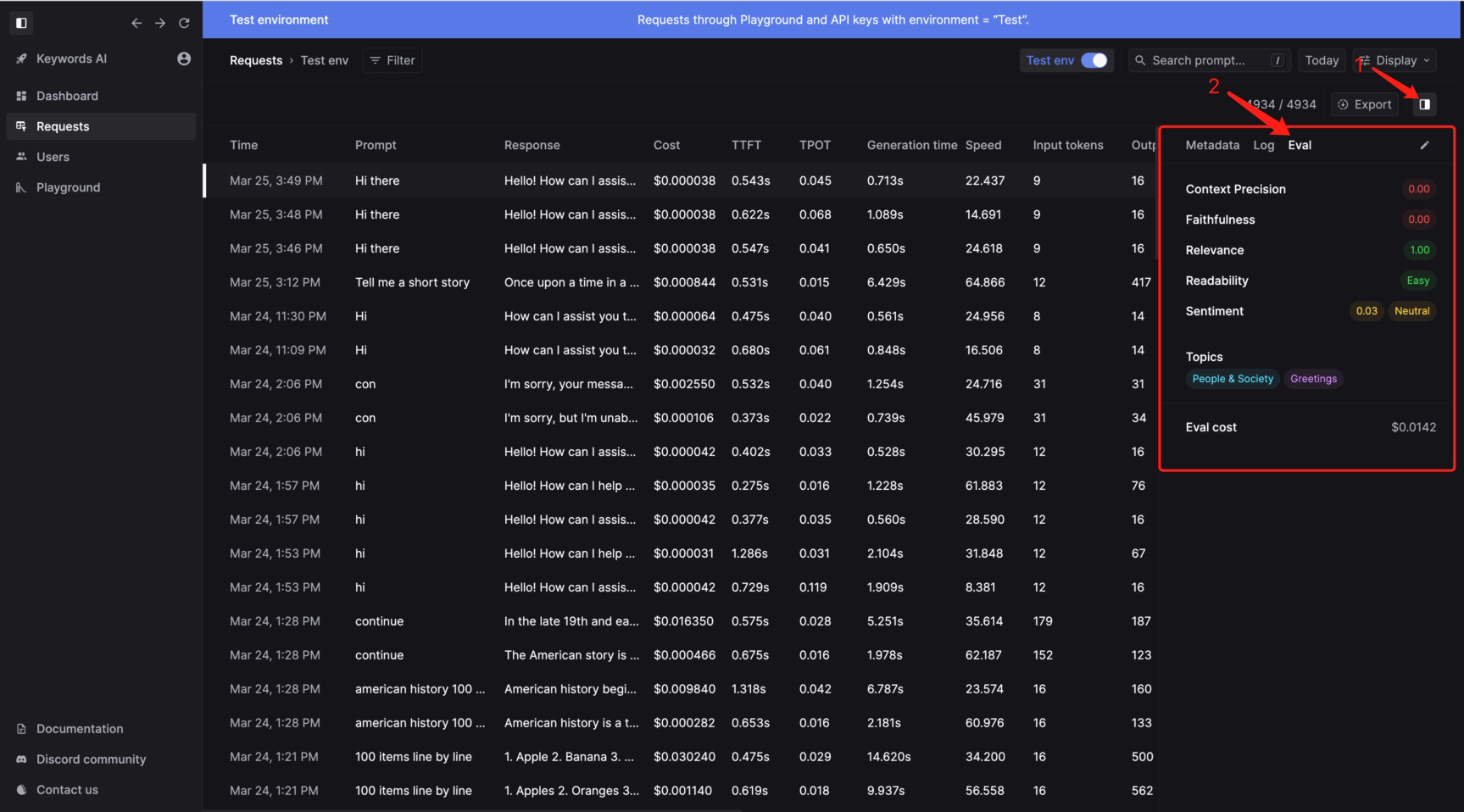
Scoring rubric in LLM prompt:
- 0.0 means that the answer is completely irrelevant to the question.
- 0.5 means that the answer is partially relevant to the question or it only partially answers the question.
- 1.0 means that the answer is relevant to the question and completely answers the question.
Settings and parameters
- Go to Keywords AI (on top of the left nav bar) > Evaluation > Text generation > Answer Relevance
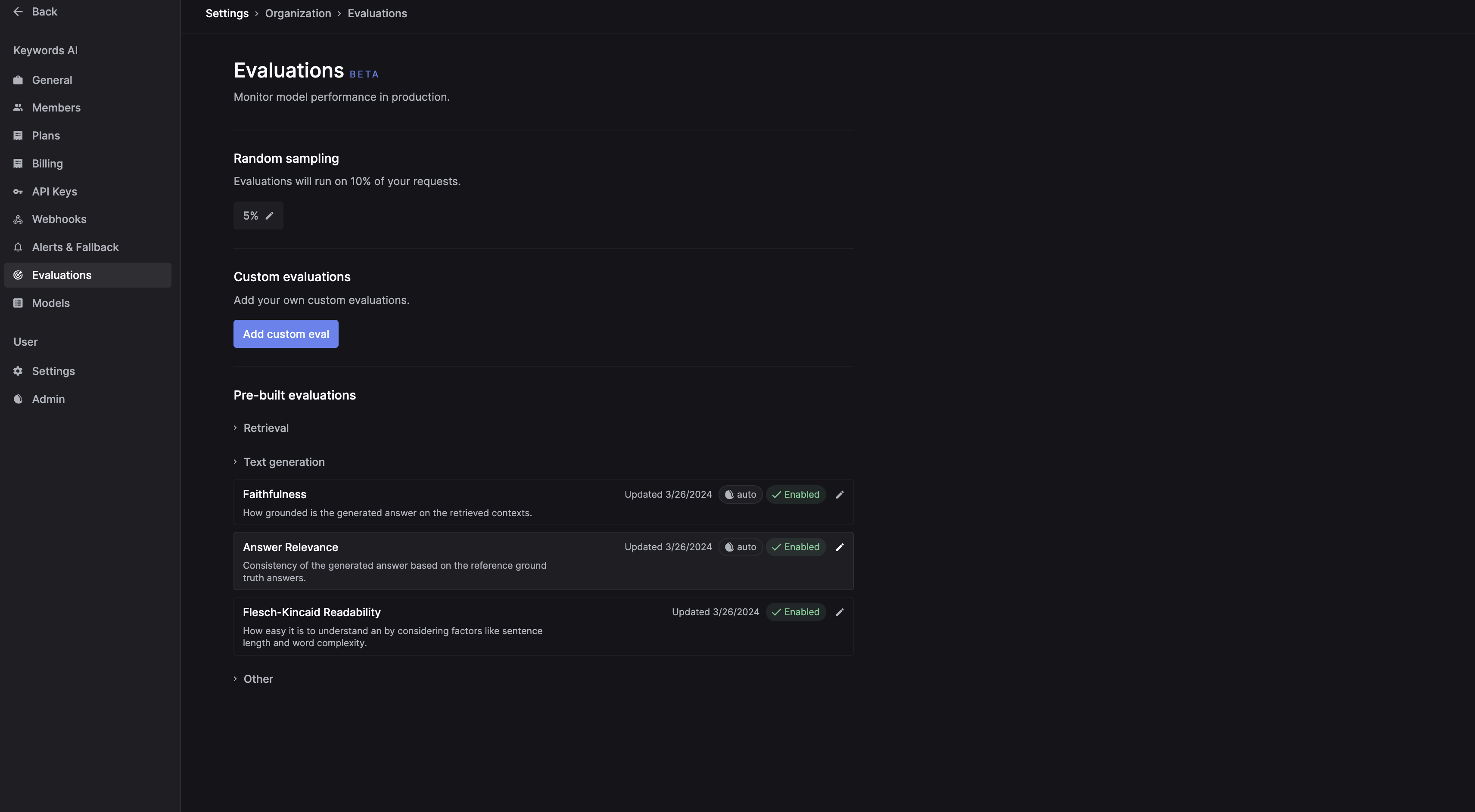
- Click on the
Flesch–Kincaidcard to create the setting:
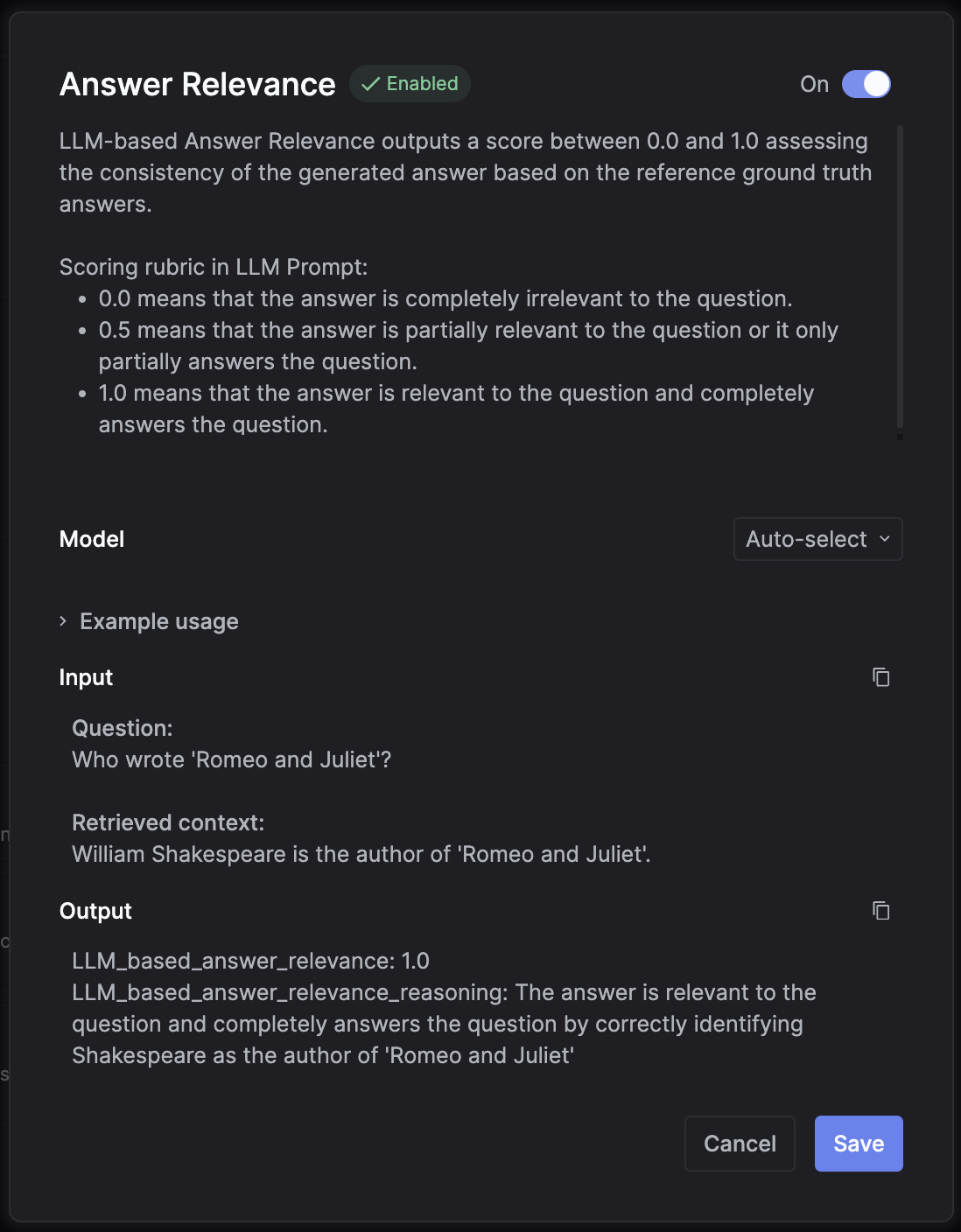
- Click the enable switch to turn on the evaluation
- Pick which LLM model you want to use for the evaluation
-
Make an API call, and the evaluation will be run based on the
Ramdom samplingsetting. - Check results in the requests log